聯想引擎
送出一個字之後,Yabomish 會自動建議下一個可能的字或詞,顯示在選字窗中。 你可以:
- 按 數字鍵 1–9 選擇聯想候選字
- 直接打碼 忽略聯想,繼續輸入
- 按 Esc 關閉聯想候選列表
聯想功能可在設定程式的「輸入」頁整體開啟或關閉。
三層架構
聯想引擎由三層資料來源組成,每一層獨立運作,結果合併後依排序呈現:
Layer 1:詞級語料
以詞為單位,根據前文在語料庫中查找接續的詞。語料來源可在設定程式中切換:
| 語料來源 | 說明 |
|---|---|
| 萌典 | 教育部辭典詞條,涵蓋標準用語 |
| 維基百科斷詞 | 中文維基百科經 CKIP 斷詞處理 |
| 新聞斷詞 | 新聞語料庫斷詞結果 |
同一時間只啟用一種語料來源。
Layer 2:詞庫
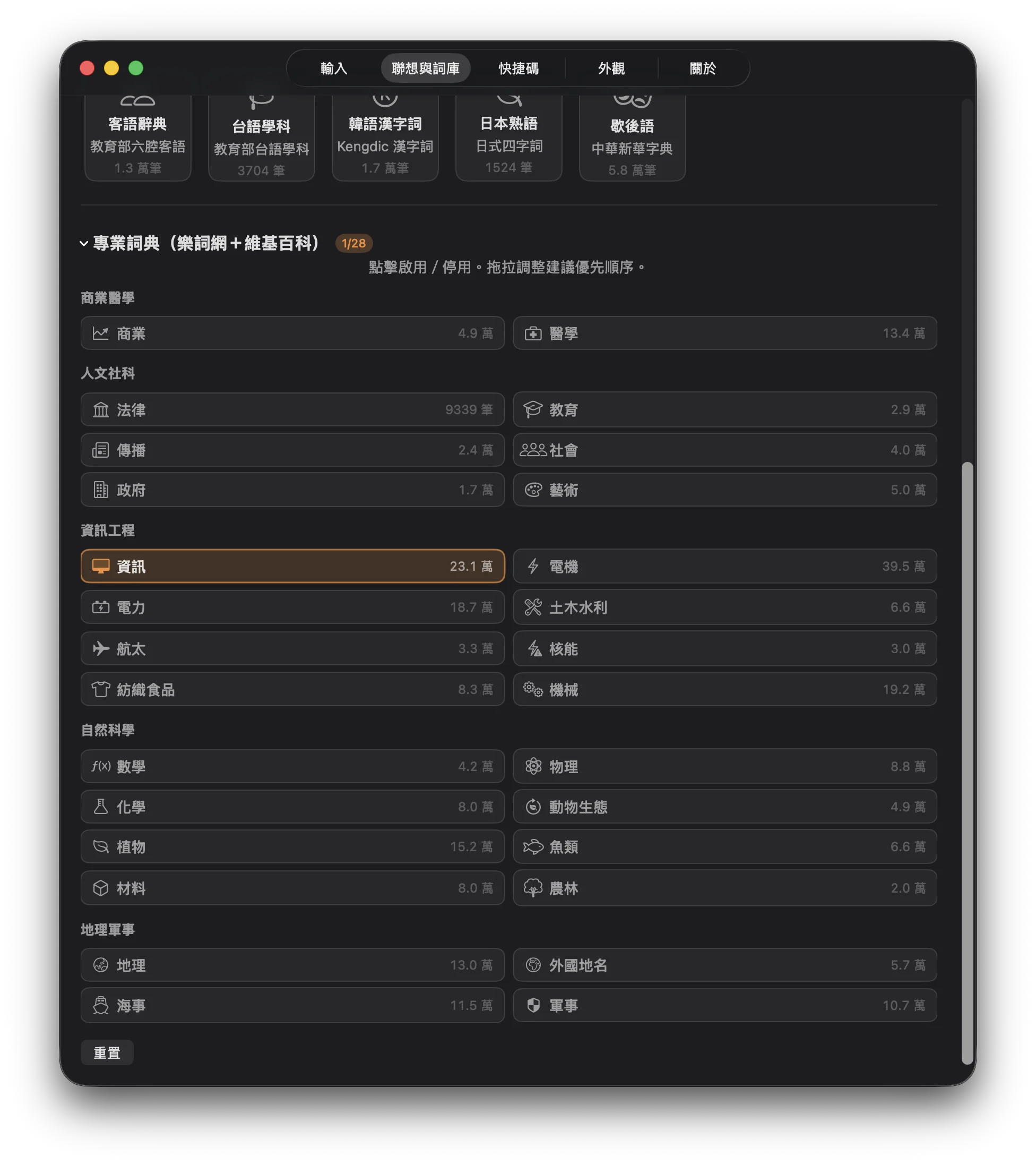
以詞組為單位,直接匹配前一字或前幾字對應的詞典條目。
一般詞庫(12 類):
| 詞庫 | 說明 |
|---|---|
| NER 詞組 | 維基百科命名實體 |
| 萌典詞組 | 教育部辭典複合詞 |
| 成語 | 教育部成語典 |
| 晶晶體 | 台式中英夾雜用語 |
| 中國流行語 | 中國網路流行用語 |
| 歇後語 | 傳統歇後語 |
| 台灣俗諺 | 教育部閩南語常用詞辭典 |
| 客語辭典 | 教育部臺灣客語辭典(六腔) |
| 台灣地名 | 教育部本土語言標注臺灣地名 |
| 學科術語 | 教育部臺灣台語學科術語 |
| 韓語漢字詞 | Kengdic 韓語漢字詞典 |
| 日本熟語 | 日語四字熟語 |
專業詞典(28 本):
資料來源為國家教育研究院樂詞網(NAER)及維基百科,分為五大類:
| 大類 | 包含領域 |
|---|---|
| 商業醫學 | 商業、經濟、會計、醫學、護理、藥學等 |
| 人文社科 | 教育、心理、社會、哲學、法律等 |
| 資訊工程 | 資訊、電機、電子、通訊、軟體工程、航太、核能、紡織食品等 |
| 自然科學 | 數學、物理、化學、動物生態、植物、魚類、地球科學等 |
| 地理軍事 | 地理、測量、軍事、海洋等 |
Layer 3:字級聯想
以單字為單位,使用 bigram 和 trigram 統計模型預測下一個字。這是最細粒度的聯想層,當詞級語料和詞庫都沒有匹配時,字級聯想仍能提供建議。
聯想策略
三層的查詢順序決定了候選字的排列優先級。你可以在設定程式的「聯想與詞庫」頁中拖拉調整順序,或選擇預設策略:
| 策略名稱 | 順序 | 適用場景 |
|---|---|---|
| 一般 (general) | 詞級 → 詞庫 → 字級 | 日常寫作(預設) |
| 詞庫優先 (domain) | 詞庫 → 詞級 → 字級 | 專業文件撰寫 |
| 字級優先 (char) | 字級 → 詞級 → 詞庫 | 偏好逐字輸入 |
除了選擇預設策略,你也可以直接拖拉三層的順序卡片,自訂任意排列。
詞庫管理
在設定程式的「聯想與詞庫」頁中,每個詞庫以卡片形式呈現:
- 啟用/停用:點擊卡片上的開關,獨立控制每個詞庫
- 調整優先順序:拖拉卡片上下移動,排在前面的詞庫結果優先顯示
- 專業詞典:依五大類分組顯示,可整組啟用或逐一選擇
💡 寫程式文件時,可以只啟用「資訊工程」類的專業詞典,並將詞庫優先策略設為 domain,讓專業術語排在最前面。
用詞習慣
Yabomish 內建國家教育研究院(NAER)兩岸用詞對照表,收錄約 82,000 組對照詞。
在設定程式的「輸入」頁中,可切換:
- 臺灣用詞:優先顯示臺灣慣用詞彙(預設)
- 中式用詞:優先顯示中國大陸慣用詞彙
切換後,對側用詞不會消失,只是在排序中降權,排到較後面的位置。例如選擇「臺灣用詞」時,「軟體」會排在「軟件」前面,但「軟件」仍然可以找到。
晶晶體
晶晶體是台式中英夾雜的用語風格(例如「這個 issue 很 tricky」)。Yabomish 將晶晶體作為獨立的聯想池處理:
- 支援單字觸發:輸入「被」可能建議「cue 到」、輸入「很」可能建議「chill」
- 晶晶體詞庫可在「聯想與詞庫」頁中獨立啟用或停用
- 不受三層順序影響,作為獨立來源混入聯想結果
Emoji 聯想
送字後,Yabomish 會依據前一個字自動建議相關的 Emoji。例如:
- 「笑」→ 😄 😂 🤣
- 「心」→ ❤️ 💕 💖
- 「火」→ 🔥 ❤️🔥
Emoji 聯想資料來自 Unicode CLDR,以擴充表形式安裝在 ~/Library/YabomishIM/tables/ 中。
虛詞結尾自動停止
當送出的字是常見虛詞時,聯想引擎會自動停止建議,避免產生無意義的候選。自動停止的虛詞包括:
的、了、嗎、呢、吧、啊、哦、喔、耶、囉、啦、嘛、哩、咧……
這讓你在句尾自然地結束輸入,不會被多餘的聯想候選干擾。
智慧排序
聯想候選字的排序結合三種統計模型:
Unigram(字頻)
- 記錄每個字的使用頻率,存於 SQLite 資料庫(
freq.db) - 每累計 500 次輸入自動執行 decay(衰減),避免早期高頻字永遠霸佔前位
- 越近期使用的字,權重越高
Bigram(前後文)
- 記錄「前一字 → 當前字」的共現頻率
- 排序時採用 adaptive stupid backoff 策略:
- bigram 命中:直接使用 bigram 機率
- bigram 未命中:fallback 至 unigram 機率 × α
- α 值自動調整:前 100 次查詢使用 0.4 暖機值,之後根據 session bigram miss rate 動態計算。bigram 覆蓋率越高 → α 越低 → bigram 鑑別力越強;覆蓋率越低 → α 越高 → 更信任 unigram
- 預設權重配比:70% unigram + 30% bigram
Trigram(三字組)
- 將前兩個字組成複合鍵
prev2|prev1,存入 bigram 表中 - 當前兩字的組合在表中有記錄時,提供更精確的預測
- 例如輸入「中華民」後,trigram 會強力推薦「國」
三種模型的分數加權合併後,決定最終的候選排序。
(06-lookup-modes.md)